

CSV & Excel Scanner
Introduction
The CSV & Excel Scanner is one of the source connectors available in migration-center starting with version 3.9. It scans data from CSV and MS Excel files and creates corresponding objects in the migration-center database. If the scanned data also contains links to content files, the CSV & Excel scanner can link those files to the created objects as well.
Prerequisites
When scanning Excel files the “Write Attributes” permission is required otherwise the scanner will throw an “Access is denied” error.
Limitations
When attempting to scan Excel files with a large number of rows and/or columns the UI might freeze until the following error is thrown:
ERROR executing job: Error was: java.lang.OutOfMemoryError: GC overhead limit exceeded
This is a limitation of the Apache POI API, and the recommendation is to convert the excel file into a CSV file.
Scanner Configuration
To create a new CSV & Excel Scanner job click on the New Scanner button and select “CSV/Excel” from the adapter type dropdown list. Once the adapter type has been selected, the parameters list will be populated with the CSV & Excel Scanner parameters.
The Properties window of a scanner can be accessed by double-clicking the scanner in the list or selecting the Properties button or entry from the toolbar or context menu.
Scanner Parameters
The common adaptor parameters are described in Common Parameters.
The configuration parameters available for the CSV & Excel Scanner are described below:
filePath*
The full path to the CSV or MS Excel file to scan.
Since the job will be executed on the job server machine, you must provide a valid relative to that machine or a UNC path.
sourceIdColumn*
The name of the column in the CSV or Excel file that contains the source ID of the object.
Note that the values in this column must be unique.
contentPathColumn
The name of the column in the CSV or Excel file that contains the path to the corresponding content file of the object.
versionIdentifierColumn
The name of the column in the CSV or Excel file that identifies all objects that belong to a specific version tree.
Mandatory when scanning versions.
versionLevelColumn
The name of the column in the CSV or Excel file that specifies the position of an object in the version tree.
Mandatory when scanning versions.
scanUpdates
Flag indicating if the modified objects will be scanned as updated objects or will be ignored. See Delta Migration
enrichMetadataForScannerRun
The run number of the scan run that you want to enrich.
Mandatory when using enrichment mode.
enrichMetadataPrefix
Optional prefix for the columns that will be added to the objects when running in enrichment mode.
multivalueFields
The names of the columns that will have multi-values separated by a delimiter.
multivalueDelimiter
The delimiter will be used to separate the values of multi-value columns.
loggingLevel*
See Common Parameters.
Parameters marked with an asterisk (*) are mandatory.
Using the CSV and Excel Scanner
The CSV & Excel scanner supports two operation modes: normal and enhancement mode. In normal mode, you can scan objects from a CSV or Excel file and those objects are saved in the corresponding scan run as new, distinct objects in the MC database. In enhancement mode, you can scan data from a CSV or Excel file that is added to an existing scan run, i.e. it enhances an existing scan run with additional data.
Normal mode: scan CSV and Excel files
In normal operation mode, you can scan objects without content, objects with content, and objects with versions from a CSV or Excel file.
Scan objects without content
In order to scan objects without content, you just specify the path to the CSV or Excel file and the name of the column that contains the unique source ID of the objects. For example:
The screenshot below shows an excerpt of CSV file you would like to scan.
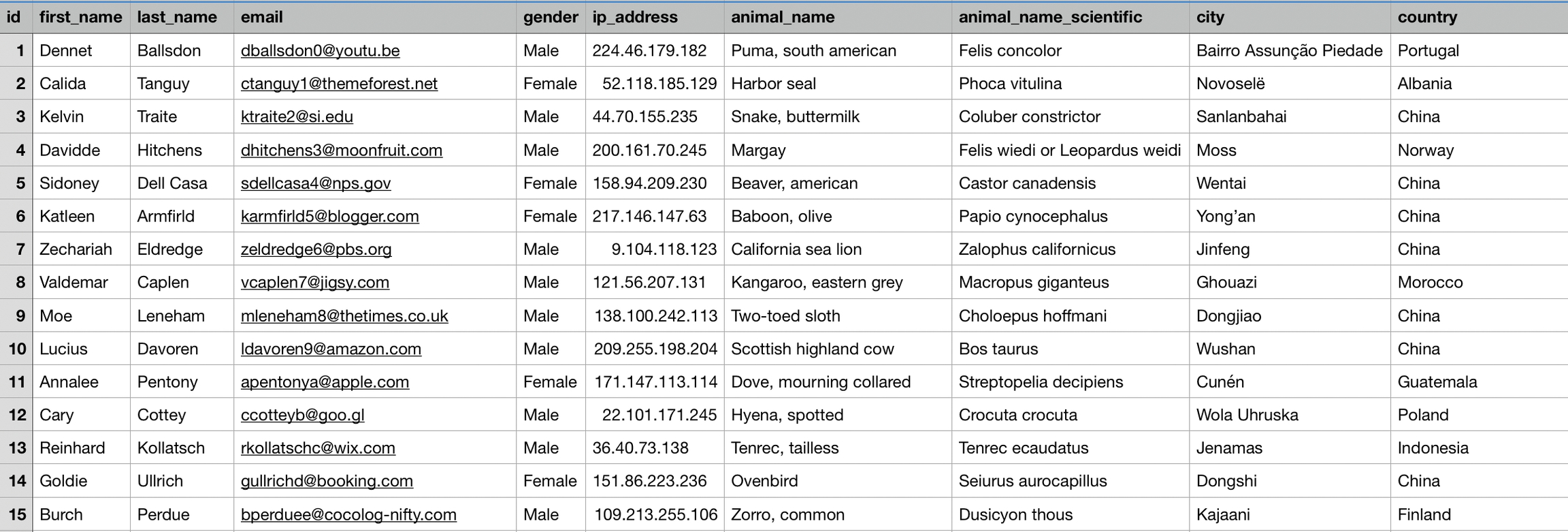
You would then enter the path to the CSV file in the “filePath” parameter and enter “id” as value in the “sourceIdColumn” parameter (because the column named “id” contains the unique IDs of the objects in the CSV file).
Scan objects with content
If your source file contained a column with a file path, as seen in the next screenshot, you can enter that column name (“profile_picture” in the example) in the “contentPathColumn” in order to scan that content file along with the metadata of the object.

Scan objects with versions
In order to scan objects with versions, your source file needs to contain two additional columns: one column that identifies all objects that belong to a specific version tree (“versionIdentifierColumn”) and another column that specifies the position of an object in the version tree (“versionLevelColumn”).
Starting with version 3.16, the scanner allows adding new versions to an existing version tree (scanned in a previous run) just by setting the specific root id.
Note: If the last version was updated, the new scanned versions will be related to the updated object.
In the example below, the source file contains metadata of documents that consist of several versions each. Each document has a “title” and a “document_id”. Each version has a “version_id” and a “content_file”. The combination of “document_id” and “version_id” must be unique. Since the content file path is unique for each version in this example, you could use that column as “sourceIdColumn”.

A valid configuration to scan the example source file could look like this:

Enrich mode: add data to existing scan runs
There are many document management applications, which reference data in third-party-systems. If you want, for example, to archive documents from such an application, it might be useful to store that referenced data also in the archive records, in order to have independent, self-contained archive records. To achieve this, you could (1) scan your document management system with the appropriate scanner, (2) export the data from the third-party-system into a CSV file, and (3) enhance the scan run from step (1) with the data from the CSV file using the CSV & Excel scanner in enhancement mode.
The source file for an enhancement mode scan needs a column that stores the source ID of the corresponding object, i.e. the object that will be enhanced with the data in the source file, in the specified scan run.
For example, the following table shows an excerpt of an existing scan run. The source ID of the objects is stored in the column “Id_in_source_system”. In this case, the ID is the full path of the files that were scanned by the scan run.
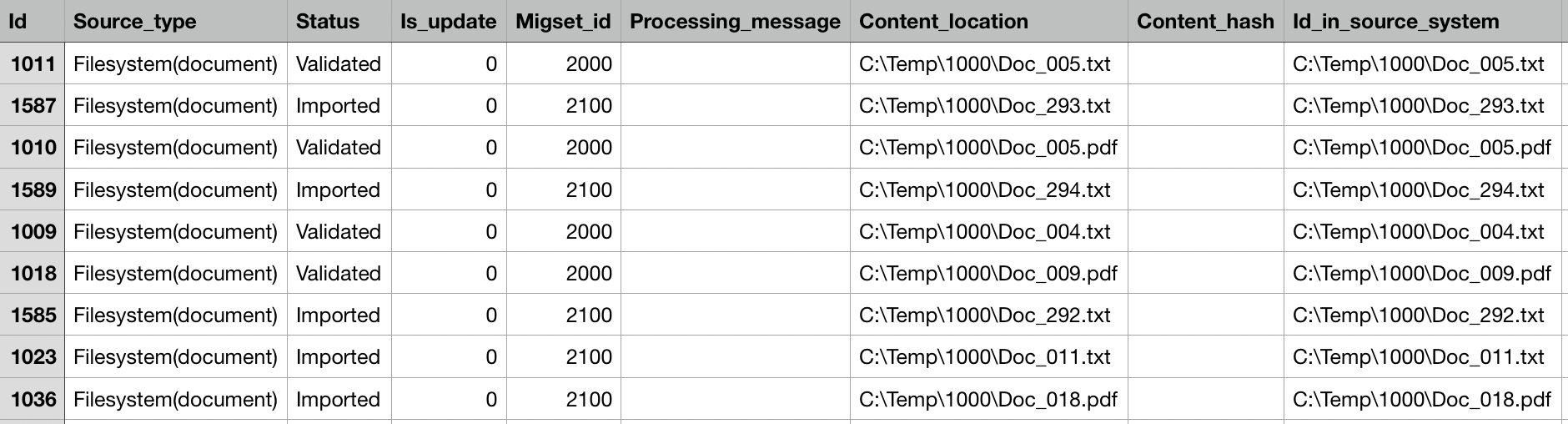
The source CSV or Excel file for the enhancement scan should contain all the data that you would like to add to the previously scanned objects and a column with the source ID of the corresponding object, as shown in the following table:

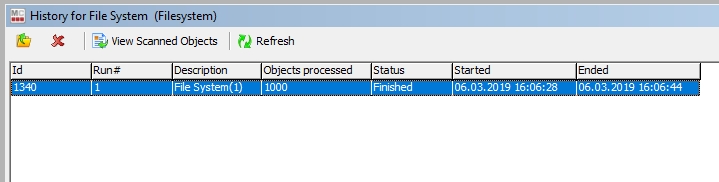
In order to run the scanner in enhancement mode, you need to enter a valid scan run ID in the parameter “enrichMetadataForScanRun”. You can find that ID in the -History- view of a scanner:
The “sourceIdColumn” parameter should contain the name of the column with the source ID. That would be “source_id” in the example above.
You can provide an optional prefix for the columns that will be added to the scan run in the “enrichMetadataPrefix” parameter. This is helpful in the case when your source file contains columns with names that already exist in the specified scan run.
Of course you can enhance a certain scan run several times with different source files.
Scan multi-value fields
The scanner allows splitting values from one or multiple columns in multiple distinct values based on a delimiter.

For example, in this particular case, if you want to split the values of columns Record_Series and Classification, all you need to do is to add the column names in the multivalueFields parameter and set the "|" delimiter in multivalueDelimiter parameter:

If the delimiter between the values will not correspond with the one that was insered in the multivalueDelimiter attribute, the cell value will be no longer considered a multi-value so it will be stored as single-value.
Limitations
The user cannot set as input for multivalueFields the value from fields sourceIdColumn, versionIdentifierColumn, or versionLevelColumn because those are single-value fields.
If the parameter multivalueFields is set then parameter multivalueDelimiter must be set as well.
Delta Migration
Starting with 3.16 of migration-center, the CSV/Excel scanner is able to scan existing objects as updates.
When the scanUpdates parameter is checked, the scanner compares the attribute values of the previously scanned object with the ones in CSV/Excel. If they are not exactly the same then the object will be scanned as an update. If they are the same, the object is ignored and an info message will be added in the report log.
When the scanUpdates parameter is not checked, the modified objects will be ignored and an info message will be logged.
Was this helpful?