Filesystem Scanner
Introduction
You can use our Filesystem Scanner in several use cases, e.g. to scan files from file repositories or to scan files exported into a filesystem from a DMS or other third-party system.
Scanner Configuration
To create a new Filesystem Scanner job, specify the respective adapter type in the Scanner Properties window – from the list of available connectors “Filesystem” must be selected. Once the adapter type has been selected, the Parameters list will be populated with the parameters specific to the selected adapter type, in this case the Filesystem connector’s.
The Properties window of a scanner can be accessed by double-clicking a scanner in the list, or selecting the Properties button/menu item from the toolbar/context menu.
A detailed description is always displayed at the bottom of the window for the currently selected parameter.
The maximum length of a path for a file system object is now 512 bytes, up from 255 bytes used in previous versions of migration-center all max supported string lengths are specified in bytes. This equals characters as long as the characters are single-byte characters (i.e. Latin characters). For multi-byte characters (as used by most languages and scripts having other than the basic Latin characters) it might result in less than the equivalent number of characters, depending on the number and byte length of multi-byte characters within the string (as used in UTF-8 encoding).
Scanner parameters
The common adaptor parameters are described in Common Parameters.
The configuration parameters available for the FileSystem Scanner are described below:
scanFolderPaths* The folder paths to be scanned.
Can be local paths or network file shares (SMB/Samba)
Multiple values can be entered by separating them with the “|” character. They also can be provided as a list of folder paths, one on each row, stored in a text file. The text file path must start with "@".
Those two methods of providing folder paths are mutually exclusive.
Examples:
scanning a network share and a local path:
\\share1\testfolder|c:\documents
scanning folders provided in a text file:
@C:\MC\folders-to-scan.txt
Note: To scan network file shares the Job Server running the respective Scanner must be configured to run using a domain account that has full read permission for the given network share.
For information about configuring the Job Server to run using a specific account, see Windows Help for configuring services to run using a different user account, since the Job Server runs as a regular Windows service.
excludeFolderPaths The folders that need to be excluded from the scan. The folder paths to be excluded from the scan must be subpaths of the “scanFolderPaths” parameter and must be specified either as an absolute or relative path. The relative path will start with "*".
Examples:
absolute path:
c:\documents\invoices\do-not-migrate
relative path:
*\excludedFolder
The scanner will automatically add each relative path the each of the folders specified in "scanFolderPaths" and add the result to the list of folders to exclude. Example: If "c:\users\Frank|c:\users\Michael" and "*\do-not-migrate" were specified in "scanFolderPaths" and "excludeFolderPaths" respectively, the scanner would skip the folders "c:\users\Frank\do-not-migrate" and "c:\users\Michael\do-not-migrate".
Multiple values can be entered by separating them with the “|” character.
Note: If the list of excluded folders contains folders that are subfolders of other folders in the same list, these are removed from the list since they are redundant.
excludeFiles Filename pattern used to exclude certain types of files from scanning. This parameter uses regular expressions.
For example to exclude all documents that have the extension “txt”, use this regular expression: (.)+\.txt
Use “|” as delimiter if you want to enter multiple exclusion patterns.
Note:
The regular expressions use syntax similar to Perl. For more technical details please read the specific javadocs page at:
http://java.sun.com/j2se/1.5.0/docs/api/java/util/regex/Pattern.html
For more information about regular expressions, please visit http://www.regular-expressions.info!
ignoreHiddenFiles Specifies whether files marked as “Hidden” in the file system should be scanned or not.
scanChangedFilesBehaviour Specifies the behavior of the scanner when a file update is detected. Accepted values are:
1 – (default) – the changed file will be added as update object
2 – the changed file will be added as a new version
3 – the changed file will be added as a new object
Format: String
For more details please consult chapter Working with Versions
moveFilesToFolder Set a valid local file system path or UNC path folder where to move the scanned files.
NOTE: The moved files are DELETED from the source location (this is not a copy).
The id_in_source_system and content_location values will reflect the new path. The new location will clone the parent folder structure of each file.
Example:
scanFolderPath = c:\source\documents
moveFilesToFolder = c:\moved\documents
The source file c:\source\documents\folderA\document.doc will be moved to c:\moved\documents\<scanRunId>\folderA\ document.doc
scanFolders If flag is checked folders will be scanned as fully editable and transformable objects. This way custom attributes, object types, owner and permissions can be defined for the folders. Otherwise folders will be retained only as path references from the documents and will be created using default folder settings in Documentum.
mcMetadataFileExtension The file-extension of the XML files which contains extra metadata for the scanned files and folders.
Note: The file extension must be specified without a dot, i.e. just "fme" and not ".fme".
For more details please consult chapter Enriching the content using metadata from external XML files
metadataXsltFile The path to XSLT file that should be applied to metadata XML files before processing. Leave it empty if metadata XML files are already in expected format.
scanExtendedMetadata Flag indicating if extended metadata will be scanned for common documents like: MS Office documents, pdf, etc. Extended metadata is extracted using apache tika library. For more information about all supported formats please refer the apache-tika documentation: http://tika.apache.org/0.9/formats.html
extendedMetadataDateFormats Can be used for setting one or more Java date formats the scanner will be used to detect the date attribute in the document content. If empty, the default list of patterns will be used
ignoredAttributesList Contains list of attributes (comma delimited) that will be ignored. All this attributes will be ignored during scanning saving performance and database storage.
computeChecksum When it's checked the checksum of scanned files will be computed. Useful for determining whether files with different names and from different locations have in fact the same content, as can frequently happen with common documents copied and stored by several users in a file share environment.
Do not enable this option unless necessary, since the performance impact is significant due to the scanner having to read the full content for each and compute the checksum for it.
hashAlgorithm Specifies the algorithm that will be used to compute the Checksum of the scanned objects.
Possible values are "MD2", "MD5", "SHA-1", "SHA-224", "SHA-256", "SHA-384" and "SHA-512". Default value is MD5.
hashEncoding Specifies the encoding that will be used to compute the Checksum of the scanned objects.
Possible values are "HEX", "Base32" and "Base64". Default value is HEX.
ignoreWarnings When it's checked the following warnings are ignored so the affected objects will be scanned:
Warning when an xml-metadata file is missing or cannot be read;
Warning when "owner name" or "creation date" cannot be extracted;
Warning when check sum cannot be computed;
Warning when extended metadata cannot be extracted;
versionIdentifierAttribute See Explicit versioning section from Working with Versions.
versionLevelAttribute See Explicit versioning section from Working with Versions.
loggingLevel* See: Common Parameters.
Parameters marked with an asterisk (*) are mandatory.
Quick guide to basic migration tasks
Basic configuration
A basic scanner configuration supposes setting a list of folders to be scanned. Local paths and UNC paths are supported. The scanner will scan all files located inside given folders and their subfolders. The common windows attributes like filename, file path, creation date, modify date, content size etc. are extracted and saved in MC database as metadata.
To scan folders as distinct objects in migration-center the flag scanFolders needs to be checked. In this case all subfolders of the given folder list will be saved in migration-center database together with their metadata.
Enriching the content using metadata from external XML files
Additional metadata stored in external files can be used to enrich the files and folders originating from the file system. This file needs to contain the XML schema used by migration-center format and adhere to the naming convention expected by migration-center. The format for such a file is described below.
Although the files’ contents are XML, the extension of such metadata files can be arbitrary and is NOT recommended to be set to XML in order to prevent potential conflicts with actual files using the XML extension. The file extension migration-center should consider as metadata files can be specified in the mcMetadataFileExtension parameter of the Filesystem scanner. If the option has been set and the metadata file for a file or folder cannot be found, an appropriate warning will be logged.
If metadata files and/or folders are not required in the first place, clear the mcMetadataFileExtension parameter to disable additional metadata processing entirely. If some files require additional metadata and others don’t, configure the mcMetadataFileExtension parameters as if all files had metadata. In this case it is safe to ignore the warnings related to missing metadata files for the documents where metadata files are not required or available.
Metadata file naming
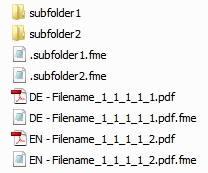
One metadata file should be available in the source system for each file and folder which is supposed to have additional metadata provided by such means. The naming for the metadata file has to follow a simple rule:
for files: filename.extension.metadataextension
for folders: .foldername. metadataextension
E.g.: If the document is named report.pdf, and the extension for the metadata files is determined to be fme, then the metadata file for this document needs to be called report.pdf.fme and fme has to be entered as the value for the mcMetadataFileExtension parameter.
If the folder is Migration the metadata file for it must be .Migration.fme.
Metadata file contents
A sample metadata file’s XML structure is illustrated below. The sample content could belong to the report.pdf.fme file mentioned above. In this case the report.pdf file has 4 attributes, each attribute being defined as a name-value pair. There are five lines because one of the attributes is a multi-value attribute. Multi-value attributes are represented by repeating the attribute element with the same name, but different value attribute (i.e. the keywords attribute is listed twice, but with different values)
The number, name and values of attributes defined in such a file are not subject to any restrictions and can be chosen freely. The value of the name attribute will appear accordingly as a source attribute in migration-center.
If the metadata file has not the expected XML structure, the scanner will use the XSLT file that should be provided before processing in metadataXsltFile, to process the enriching metadata from the file.
Multi-value attributes can be defined by repeating the attribute element with the same name, but different value attribute.
Once the document and any additional metadata have been scanned, migration-center no longer differentiates between attributes originating from different sources. Attributes resulting from metadata files will appear alongside the regular attributes extracted from the file system properties but they are prefixed with “xml_“. The full transformation functionality is available for these attributes.
In case date/time type values are included in the metadata file, the date/time formats used must comply with the date/time pattern defined for migration-center during installation. For more information see the Installation Guide.
Extracting extended metadata from the content of files
In addition to metadata obtained from the standard file system properties and metadata added via external metadata files, the Filesystem Scanner can also extract metadata from supported document formats. This type of metadata is called external metadata. The corresponding functionality can be toggled in the Filesystem Scanner via the “scanExtendedMetadata” parameter.
The scanner can parse the following file formats for metadata:
HyperText Markup Language
XML and derived formats
Microsoft Office document formats
OpenDocument Format
Portable Document Format
Electronic Publication Format
Rich Text Format
Compression and packaging formats
Text formats
Audio formats
Image formats
Video formats
Java class files and archives
The mbox format
Metadata extracted from these files will be added to the respective documents metadata. Extended metadata source attributes will be prefixed with “ext_“ to indicate their source. Apart from their naming, these attributes are not handled differently by migration-center. Just as with attributes provided via metadata files, extended attributes will appear and work alongside the standard file system attributes. The full transformation functionality is available for these attributes.
Working with Versions
A standard file system in Windows or Linux doesn't have any integrated versioning mechanism. However the Filesystem scanner has two ways of processing versions from such a filesystem.
By running multiple scans over the same files (delta migration) and processing any changed file as a new version to the previously scanned one: implicit versioning
By using versioning information from external XML files to create link separate files into a single version tree: explicit versioning
Implicit versioning
To scan versions implicitly during a Delta Scan, you need to set the scanChangedFilesBehaviour parameter to the value 2.
This parameter can take the following values:
1 - the changed file will be added as update object. This means that during import the object already imported with migration-center will be updated (i.e. overwritten) with the new attributes of the modified object, directly in the target system. (default value)
2 - the changed file will be added as a new version of the existing object. This means that a new version of the document will be created, its parent will be set to the previous version and the level in version tree will be incremented by 1.
3 - the changed file will be added as a new separate object. If the user does not change the object’s name in migration-center, the document is imported in the target repository with the same name and linked under the same folder as the original object, if this is supported by the target system.
A file is detected as changed if either its content or its metadata file has been modified since the previous scan.
If scanFolders is used, a folder is detected as changed if its metadata file has been modified since the previous scan. In this case it is saved as an update.
Explicit versioning
To scan versions explicitly you need an external XML file. The file must to contain two attributes and you need to set them in the scanner on the following parameters: versionIdentifierAttribute and versionLevelAttribute. Both parameters must be set.
The attribute names need to be prefixed with the xml_ prefix.
i.e. xml_version_id if the attribute name inside the XML file is called version_id
versionIdentifierAttribute specifies the attribute which identifies a version tree/group. All objects that are part of the same version tree should have the same value for this attribute. Any string value is permitted as long as it fulfills the previous requirement.
versionLevelAttribute specifies the attribute which identifies the order of objects in a version tree. The values must be distinct for all objects within the same version tree (i.e. that have the same versionIdentifierAttribute value) The values must be positive numbers that fit the following format:
'9999999.999999'The decimal point and the value value after it may be omitted.
Setting these parameters to attributes containing valid information will allow the Filesystem Scanner to linked objects together to form versions. This information can then be understood and processed by migration-center importers which support versioning.
Limitations
The explicit versioning is not applied in the following cases:
the attribute names versionIdentifierAttribute and versionLevelAttribute are invalid
attribute value used for versionLevelAttribute is not a number for one or more scanned documents
Before version 3.16 the explicit versioning was only applied to the objects in the current scanner run. Since 3.16, if a new version are be added to the versions trees that were created by previous scanner runs. Nevertheless, this only applies if all scanner runs belong to the same scanner.
Last updated